Leave a Comment
1.概述
在《Kafka实战-入门》一篇中,为大家介绍了Kafka的相关背景、原理架构以及一些关键知识点,本篇博客为大家来赘述一下Kafka Cluster的相关内容,下面是今天为大家分享的目录:
- 基础软件的准备
- Kafka Cluster的部署
- Send Messages
- HA特性
下面开始今天的内容分享。
2.基础软件的准备
2.1 ZK
由于Kafka Cluster需要依赖ZooKeeper(后面简称ZK)集群来协同管理,所以这里我们需要事先搭建好ZK集群,关于ZK的集群搭建,大家可以参考我写的《配置高可用的Hadoop平台》,这篇文章中我介绍了如何去搭建ZK,这里就不多赘述,本篇博客为大家介绍如何去搭建Kafka Cluster。
2.2 Kafka
由于Kafka已经贡献到Apache基金会了,我们可以到Apache的官方网站上去下载Kafka的基础安装包,下载地址如下所示:
Kafka安装包 [下载地址]
Kafka源代码 [下载地址]
这里,我们直接使用官方编译好的安装包进行Kafka Cluster的安装部署。下面我们来开始Kafka Cluster的搭建部署。
3.Kafka Cluster的部署
首先,我们将下载好的Kafka基础安装包解压,命令如下所示:
- 解压Kafka
[hadoop@dn1 ~]$ tar -zxvf kafka_2.9.1-0.8.2.1.tgz
- 进入到Kafka解压目录
[hadoop@dn1 ~]$ cd kafka_2.9.1-0.8.2.1
- 配置环境变量
[hadoop@dn1 ~]$ vi /etc/profile
export KAFKA_HOME=/home/hadoop/kafka_2.11-0.8.2.1 export PATH=$PATH:$KAFKA_HOME/bin
- 配置Kafka的zookeeper.properties
# the directory where the snapshot is stored. dataDir=/home/hadoop/data/zk # the port at which the clients will connect clientPort=2181 # disable the per-ip limit on the number of connections since this is a non-production config maxClientCnxns=0
- 配置server.properties
# The id of the broker. This must be set to a unique integer for each broker. broker.id=0
注:这里配置broker的时候,每台机器上的broker保证唯一,从0开始。如:在另外2台机器上分别配置broker.id=1,broker.id=2
- 配置producer.properties
# list of brokers used for bootstrapping knowledge about the rest of the cluster # format: host1:port1,host2:port2 ... metadata.broker.list=dn1:9092,dn2:9092,dn3:9092
- 配置consumer.properties
# Zookeeper connection string # comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002" zookeeper.connect=dn1:2181,dn2:2181,dn3:2181
至此,Kafka Cluster部署完成。
4.Send Messages
4.1启动
首先,在启动Kafka集群服务之前,确保我们的ZK集群已启动,下面我们启动Kafka集群服务。启动命令如下所示:
[hadoop@dn1 kafka_2.11-0.8.2.1]$ kafka-server-start.sh config/server.properties &
注:其他2个节点参照上述方式启动。
另外,启动其他节点的时候,在最先开始启动的节点会显示其它节点加入的信息记录,如下图所示:

4.2验证启动进程
[hadoop@dn1 kafka_2.11-0.8.2.1]$ jps 2049 QuorumPeerMain 2184 Kafka 2233 Jps
4.3创建Topic
在服务启动后,我们开始创建一个Topic,命令如下所示:
[hadoop@dn1 ]$ kafka-topics.sh --zookeeper dn1:2181,dn2:2181,dn3:2181 --topic test1 --replication-factor 3 --partitions 1 --create
然后,我们查看该Topic的相关信息,命令如下所示:
[hadoop@dn1 ]$ kafka-topics.sh --zookeeper dn1:2181,dn2:2181,dn3:2181 --topic test1 --describe
预览信息如下图所示:

下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
- Leader:负责处理消息的读和写,Leader是从所有节点中随机选择的。
- Replicas:列出了所有的副本节点,不管节点是否在服务中。
- Isr:是正在服务中的节点
4.4生产消息
下面我们使用kafka的Producer生产一些消息,然后让Kafka的Consumer去消费,命令如下所示:
[hadoop@dn1 ]$ kafka-console-producer.sh --broker-list dn1:9092,dn2:9092,dn3:9092 --topic test1

4.4消费消息
接着,我们在另外一个节点启动消费进程,来消费这些消息,命令如下所示:
[hadoop@dn2 ]$ kafka-console-consumer.sh --zookeeper dn1:2181,dn2:2181,dn3:2181 --from-beginning --topic test1
消费记录如下图所示:

5.HA特性
这里,从上面的截图信息可以看出,在DN1节点上Kafka服务上Lead,我们先将DN1节点的Kafka服务kill掉,命令如下:
[hadoop@dn1 config]$ jps 2049 QuorumPeerMain 2375 Jps 2184 Kafka [hadoop@dn1 config]$ kill -9 2184
然后,其他节点立马选举出了新的Leader,如下图所示:

下面,我们来测试消息的生产和消费,如下图所示:
- 生产消息

- 消费消息
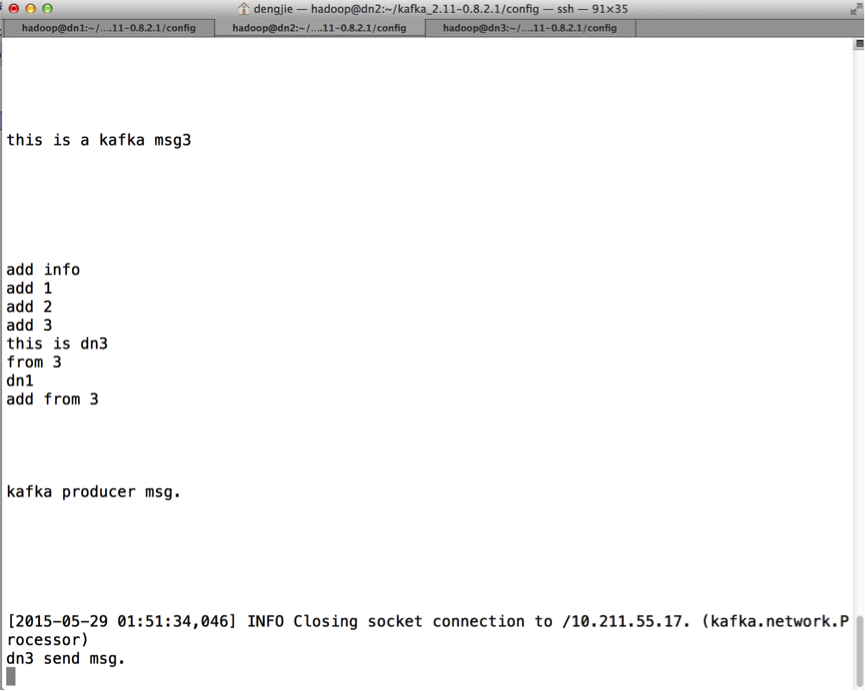
通过测试,可以发现,Kafka的HA特性还是不错的,拥有不错的容错机制。
6.总结
这里,在部署Kafka Cluster的时候,有些地方需要我们注意,比如:在我们启动Kafka集群的时候,确保ZK集群启动,另外,在配置Kafka配置文件信息时,确保ZK的集群信息配置到相应的配置文件中,总体来说,配置还算较为简单,需要在部署的时候,仔细配置各个文件即可。