Leave a Comment
https://code.facebook.com/posts/685565858139515/needle-in-a-haystack-efficient-storage-of-billions-of-photos/
http://www.sohu.com/a/112191770_222486
作者简介
陈闯,花名“战士雷欧”,白山云科技超级攻城狮。
Linux内核、nginx模块、存储架构开发老司机,7年以上存储架构、设计及开发经验,先后就职于东软、中科曙光、新浪、美团,擅长独立进行Haystack、纠删码等各种项目研发,爱好不断降低IO、挑战冗余度底线。白山滑板车选手专业十级,会漂移,正积极备战方庄街道第6届动感滑板车运动会,家庭梦想是为爱妻赢得无硅油洗发水。
正文
背景:
当今互联网,数据呈现爆炸式增长,社交网络、移动通信、网络视频、电子商务等各种应用往往能产生亿级甚至十亿、百亿级的海量小文件。由于在元数据管理、访问性能、存储效率等方面面临巨大的挑战,海量小文件问题成为了业界公认的难题。
业界的一些知名互联网公司,也对海量小文件提出了解决方案,例如:著名的社交网站Facebook,存储了超过600亿张图片,专门推出了Haystack系统,针对海量小图片进行定制优化的存储。
白山云存储CWN-X,针对小文件问题,也推出独有的解决方案,我们称之为Haystack_plus。该系统提供高性能数据读写、数据快速恢复、定期重组合并等功能。
Facebook的Haystack简介:
Facebook的Haystack对小文件的解决办法是合并小文件。将小文件数据依次追加到数据文件中,并且生成索引文件,通过索引来查找小文件在数据文件中的offset和size,对文件进行读取。
Haystack的数据文件部分:

Haystack的数据文件,将每个小文件封装成一个needle,包含文件的key、size、data等数据信息。所有小文件按写入的先后顺序追加到数据文件中。
Haystack的索引文件部分:
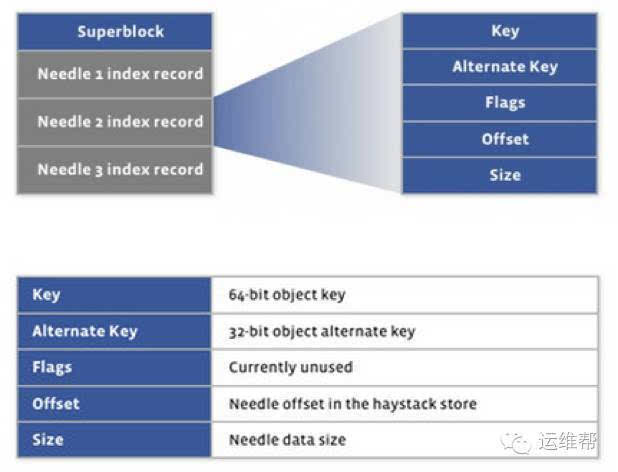
Haystack的索引文件保存每个needle的key,以及该needle在数据文件中的offset、size等信息。程序启动时会将索引加载到内存中,在内存中通过查找索引,来定位在数据文件中的偏移量和大小。
面临的问题:
Facebook的Haystack特点是将文件的完整key都加载到内存中,进行文件定位。机器内存足够大的情况下,Facebook完整的8字节key可以全部加载到内存中。
但是现实环境下有两个主要问题:
1.存储服务器内存不会太大,一般为32G至64G;
2.小文件对应的key大小难控制,一般选择文件内容的MD5或SHA1作为该文件的key。
场景举例:
一台存储服务器有12块4T磁盘,内存为32GB左右。
服务器上现需存储大小约为4K的头像、缩略图等文件,约为10亿个。
文件的key使用MD5,加上offset和size字段,平均一个小文件对应的索引信息占用28字节。
在这种情况下,索引占用内存接近30GB, 磁盘仅占用4TB。内存消耗近100%,磁盘消耗只有8%。
所以索引优化是一个必须要解决的问题。
Haystack_plus:
Haystack_plus的核心也由数据文件和索引文件组成。
1. Haystack_plus的数据文件:
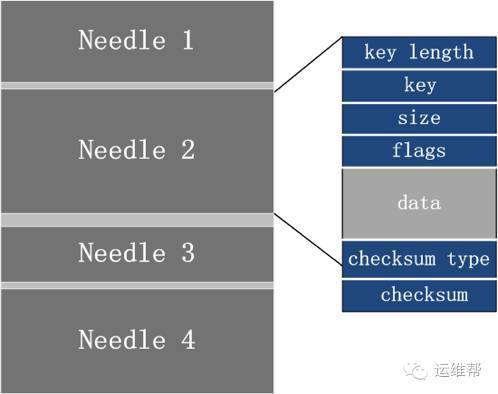
与Facebook的Haystack类似,Haystack_plus将多个小文件写入到一个数据文件中,每个needle保存key, size, data等信息。
2. Haystack_plus的索引文件:
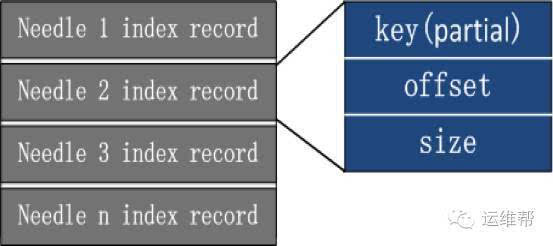
索引是我们主要优化的方向:
1. 索引文件只保存key的前四字节,而非完整的key;
2. 索引文件中的offset和size字段,通过512字节对齐,节省1个字节;并根据整个Haystack_plus数据文件实际大小计算offset和size使用的字节数。
3. Haystack_plus的不同之处:
数据文件中的needle按照key的字母顺序存放。
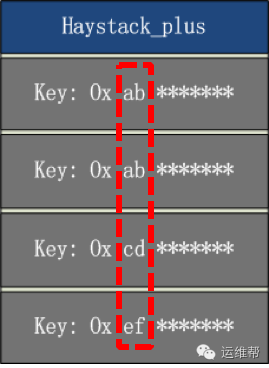
由于索引文件的key,只保存前四字节,如果小文件key的前四字节相同,不顺序存放,就无法找到key的具体位置。可能出现如下情况:
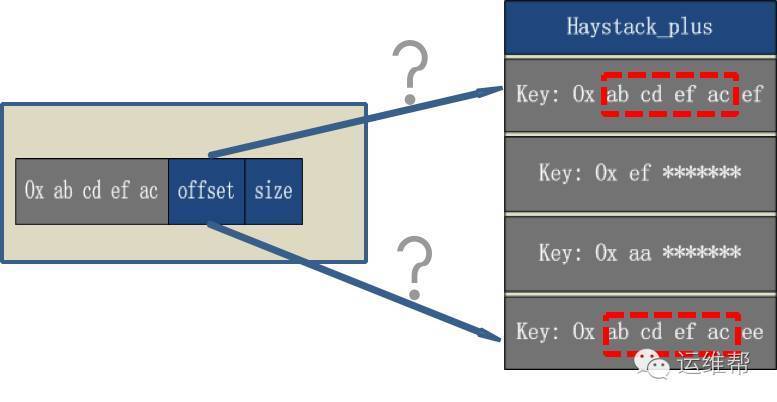
例如:用户读取的文件key是0x ab cd ef ac ee,但由于索引文件中的key只保存前四字节,只能匹配0x ab cd ef ac这个前缀,此时无法定位到具体要读取的offset。
我们可以通过needle顺序存放,来解决这个问题:
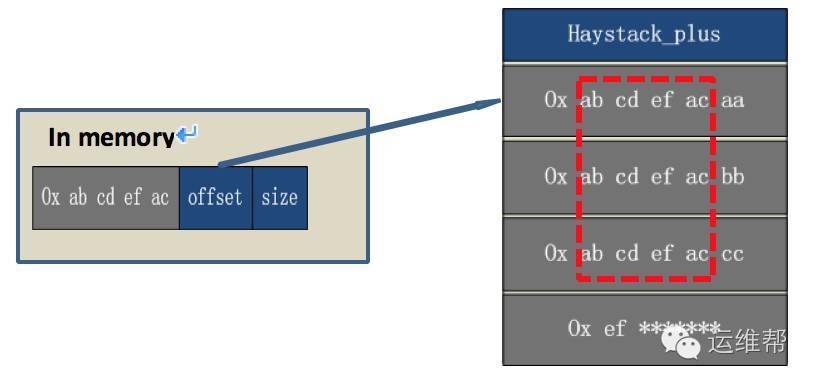
例如:用户读取文件的key是0x ab cd ef ac bb,匹配到0x ab cd ef ac这个前缀,此时offset指向0x ab cd ef ac aa这个needle,第一次匹配未命中。
通过存放在needleheader中的size,我们可以定位0x ab cdef ac bb位置,匹配到正确needle,并将数据读取给用户。
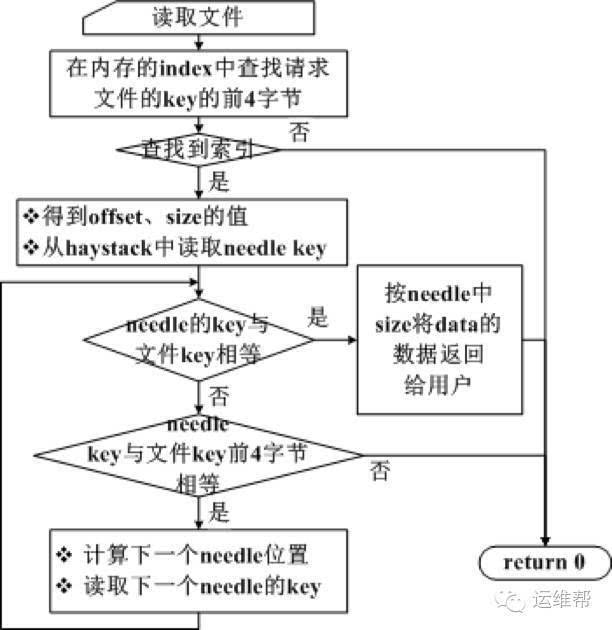
4. 索引搜索流程为:
5. 请求不存在的文件:
问题:
我们应用折半查找算法在内存查找key ,时间复杂度为O(log(n)),其中n为needle数目。索引前缀相同时,需要在数据文件中继续查找。此时访问的文件不存在时,容易造成多次IO查找。
解决方法:
在内存中,将存在的文件映射到 bloomfilter中。此时只需要通过快速搜索,就可以排除不存在的文件。
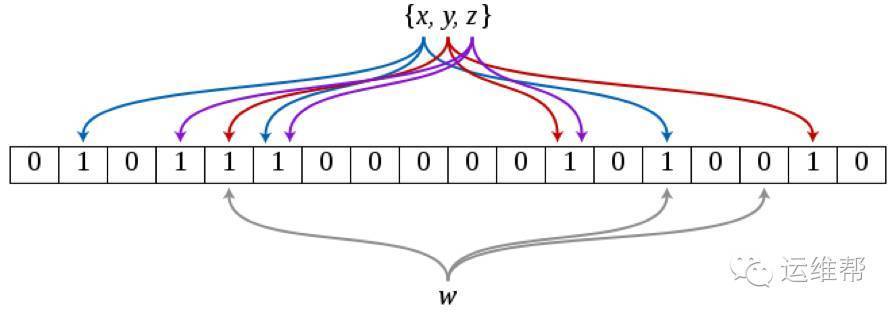
时间复杂度为 O(k), k为一个元素需要的bit位数。当k为9.6时,误报率为1%,如果k再增加4.8,误报率将降低为0.1%。
6. 前缀压缩,效果如何:
与Facebook Haystack对内存消耗:
场景举例:
文件(如:头像、缩略图等)大小4K,key为MD5
Facebook的Haystack:
key: 使用全量的key,为16字节。
offset, size:needle为追加写入,因此offset和size大小固定,offset为8字节,size为4字节。
Haystack_plus:
key: 使用key的前4字节,为4字节。
offset: 根据Haystack_plus数据文件的地址空间计算字节数,并按512字节对齐,为 4字节。
size: 根据实际文件的大小计算字节数,并按512对齐,为1字节。
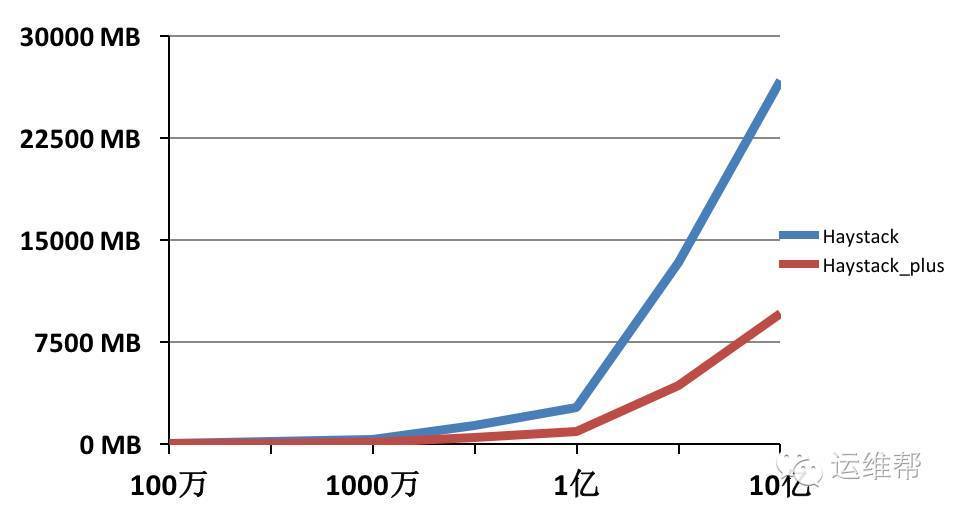
从上图可以看出在文件数量为10亿的情况下,使用Facabook的Haystack消耗的内存超过26G,使用Haystack_plus仅消耗9G多内存,内存使用降低了2/3。
7.索引优化根本就停不下来:
10 亿 个4K小文件,消耗内存超过9G。
Key占用4字节,Offset占用4字节,还需要再小一些。
下面介绍索引分层:
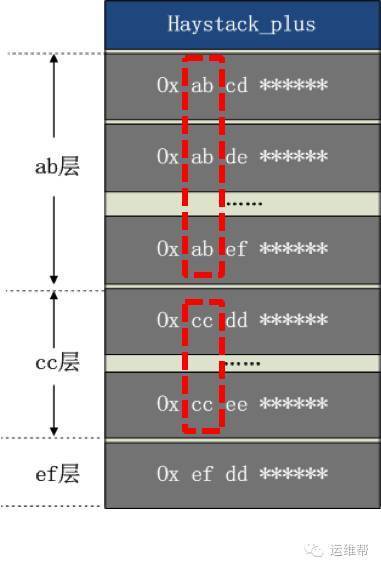
根据文件key的前缀,进行分层,相同的前缀为一层。
分层的好处:
(1)减少key的字节数:
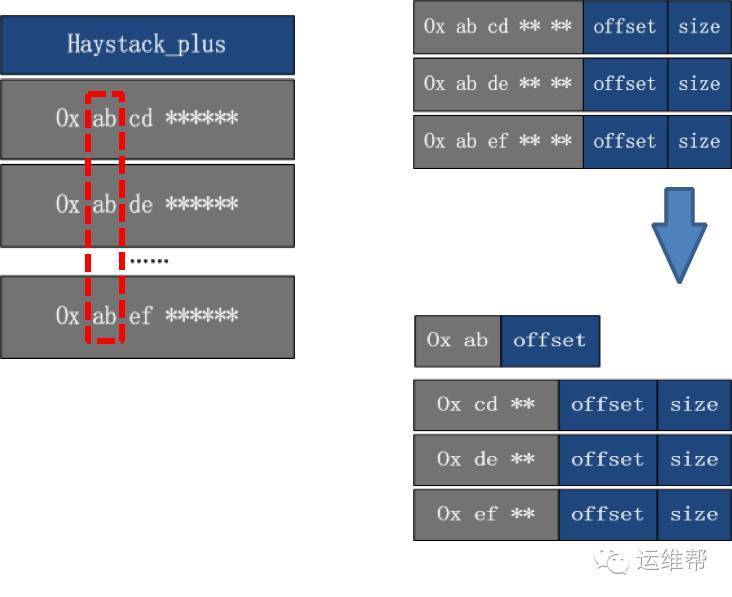
通过分层,只保存一份重复的前缀,节省key的字节数。
(2)减少offset的字节数:
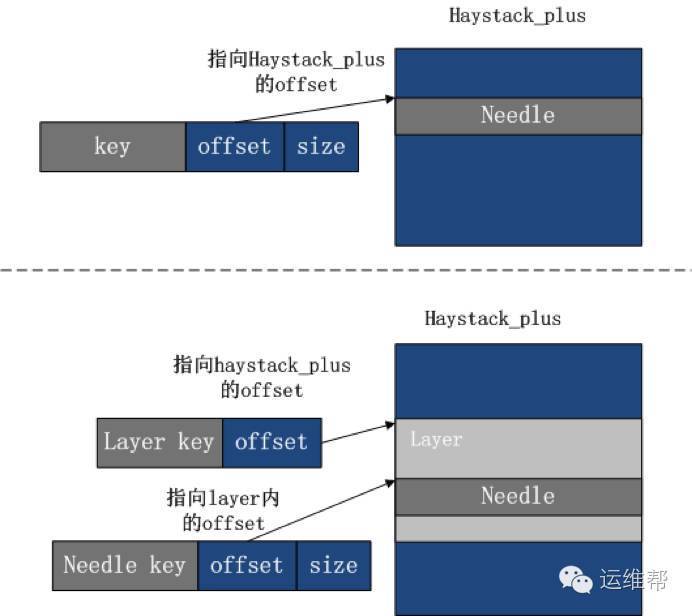
优化前的offset,偏移范围为整个Haystack_plus的数据文件的地址空间。
优化后,只需在数据文件中的层内进行偏移,根据最大的层地址空间可以计算所需字节数,
分层后的效果:
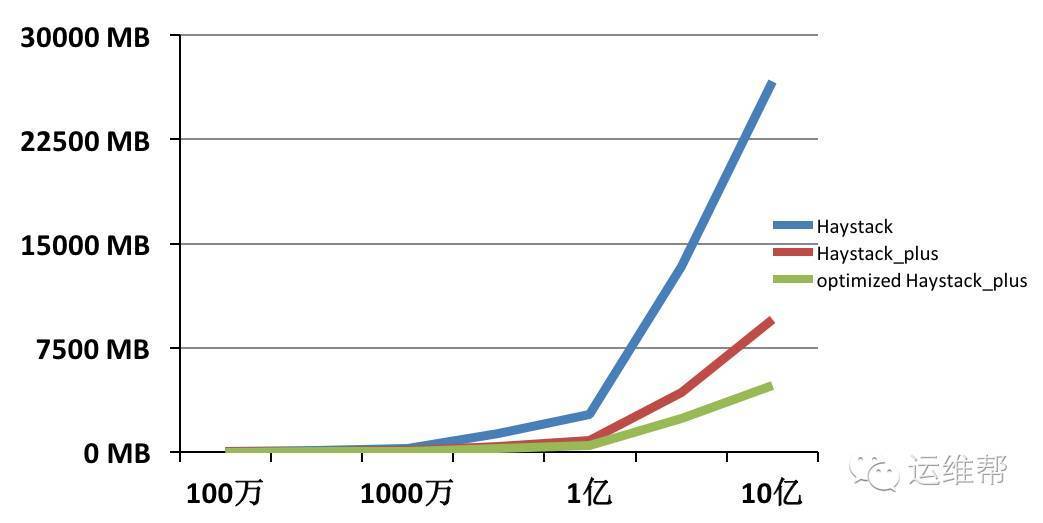
从上图可以看出,进行分层后,内存消耗从优化前的9G多,降低到4G多,节省了一半的内存消耗。
Haystack_plus整体架构:
1.Haystack_plus组织:
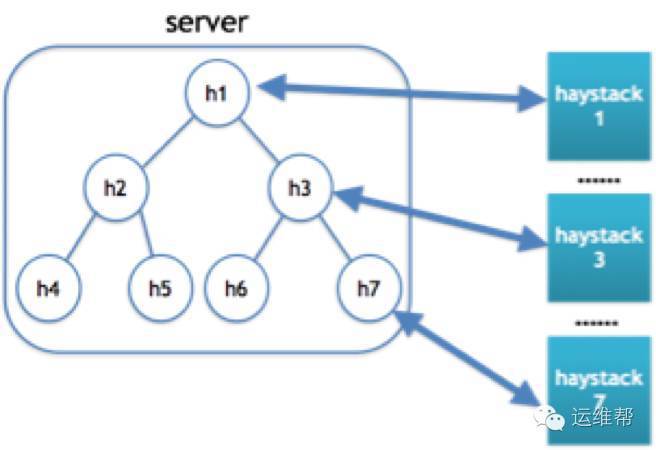
每台服务器上,我们将所有文件分成多个group,每个group创建一个Haystack_plus。系统对所有的Haystack_plus进行统一管理。
读、写、删除等操作,都会在系统中定位操作某个Haystack_plus,然后通过索引定位具体的needle,进行操作。
2.索引组织
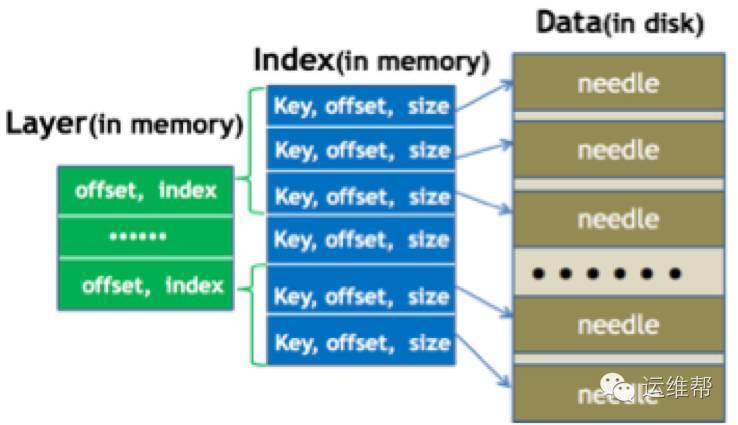
之前已经介绍过,所有needle顺序存放,索引做前缀压缩,并分层。
3.文件组成:
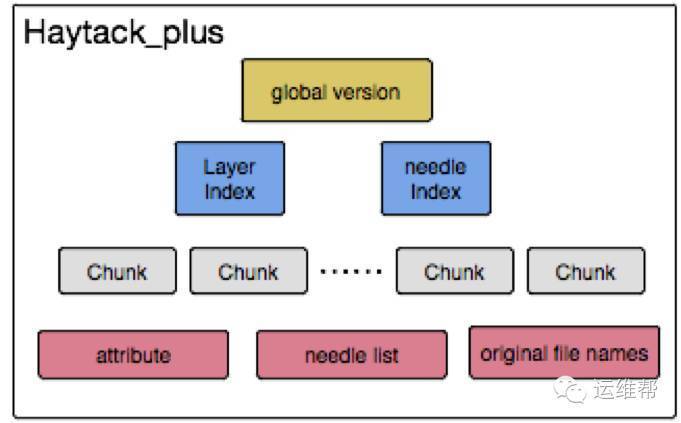
chunk文件: 小文件的实际数据被拆分保存在固定数量的chunk数据文件中,默认为12个数据块;
needle list文件: 保存每个needle的信息(如文件名、offset等);
needle index 和layerindex文件: 保存needle list在内存中的索引信息;
global version文件: 保存版本信息,创建新version时自动将新版本信息追加到该文件中;
attribute文件: 保存系统的属性信息(如chunk的SHA1等);
original filenames: 保存所有文件原始文件名。
(1)Haystack_plus数据文件被拆分为多个chunk组织,chunk1,chunk2,chunk3 ….
(2)分成多个chunk的好处:
数据损坏时,不影响其它chunk的数据;
数据恢复时,只需恢复损坏的chunk。
(3)每个chunk的SHA1值存放在attribute文件中。
4.版本控制:
由于needle在数据文件中按key有序存放,为不影响其顺序,新上传的文件无法加入Haystack_plus,而是首先被保存到hash目录下,再通过定期自动合并方式,将新文件加入到Haystack_plus中。
合并时将从needle_list文件中读取所有needle信息,将删除的needle剔除,并加入新上传的文件,同时重新排序,生成chunk数据文件、索引文件等。
重新合并时将生成一个新版本Haystack_plus。版本名称是所有用户的文件名排序的SHA1值的前4字节。
每半个月系统自动进行一次hash目录检查,查看是否有新文件,并计算下所有文件名集合的SHA1,查看与当前版本号是否相同,不同时说明有新文件上传,系统将重新合并生成新的数据文件。
同时,系统允许在hash目录下超过指定的文件数时,再重新创建新版本,从而减少重新合并次数。

版本的控制记录在global_version文件中,每次创建一个新版本,版本号和对应的crc32将追加到global_version文件(crc32用于查看版本号是否损坏)。
每次生成新版本时,自动通知程序重新载入索引文件、attribute文件等。
5.数据恢复:
用户的文件将保存成三副本存放,因此Haystack_plus也会存放在3台不同的机器上。
恢复场景一:
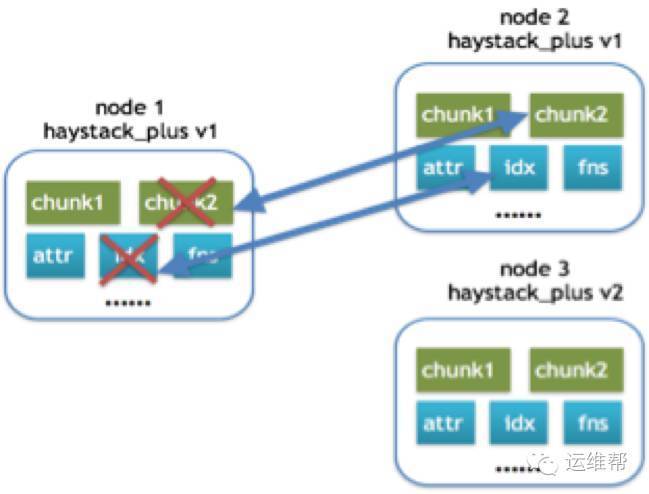
当一个Haystack_plus的文件损坏时,会在副本机器上,查找是否有相同版本的Haystack_plus,如果版本相同,说明文件的内容都是一致,此时只需将要恢复的文件从副本机器下载下来,进行替换。
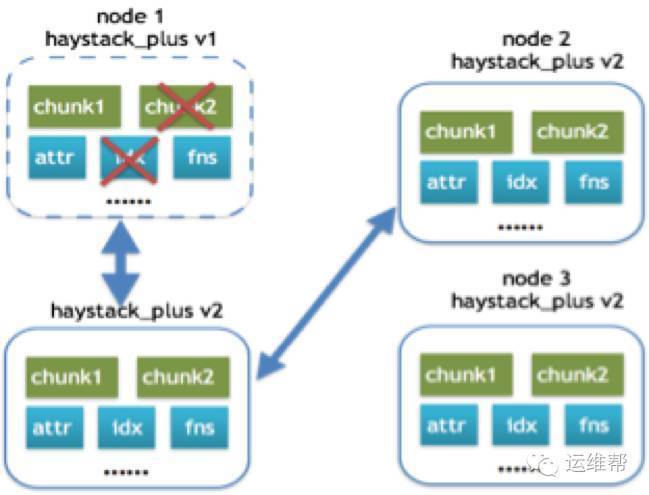
恢复场景二:
如果副本机器没有相同版本的Haystack_plus,但存在更高版本,那此时可以将该版本的整个Haystack_plus从副本机器上拷贝下来,进行替换。
恢复场景三:
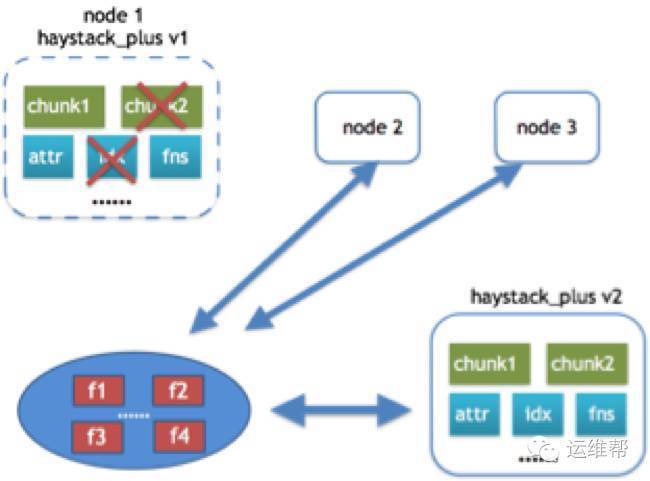
如果前两种情况都不匹配,那就从另外两台副本机器上,将所有文件都读到本地上的hash目录下,并将未损坏的chunk中保存的文件也提取到hash目录下,用所有文件重新生成新版本的Haystack_plus。
Haystack_plus效果如何:
在使用Haystack_plus后一段时间,我们发现小文件的整体性能有显著提高,RPS提升一倍多,机器的IO使用率减少了将近一倍。同时,因为优化了最小存储单元,碎片降低80%。
使用该系统我们可以为用户提供更快速地读写服务,并且节省了集群的资源消耗