Leave a Comment
https://www.cnblogs.com/zdfjf/p/5646525.html
Confluent Quick Start: https://docs.confluent.io/3.0.0/quickstart.html#quickstart
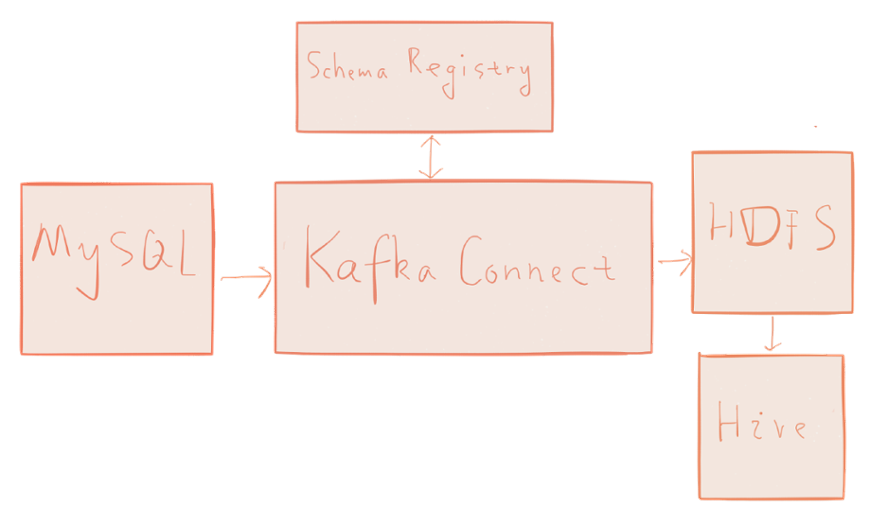
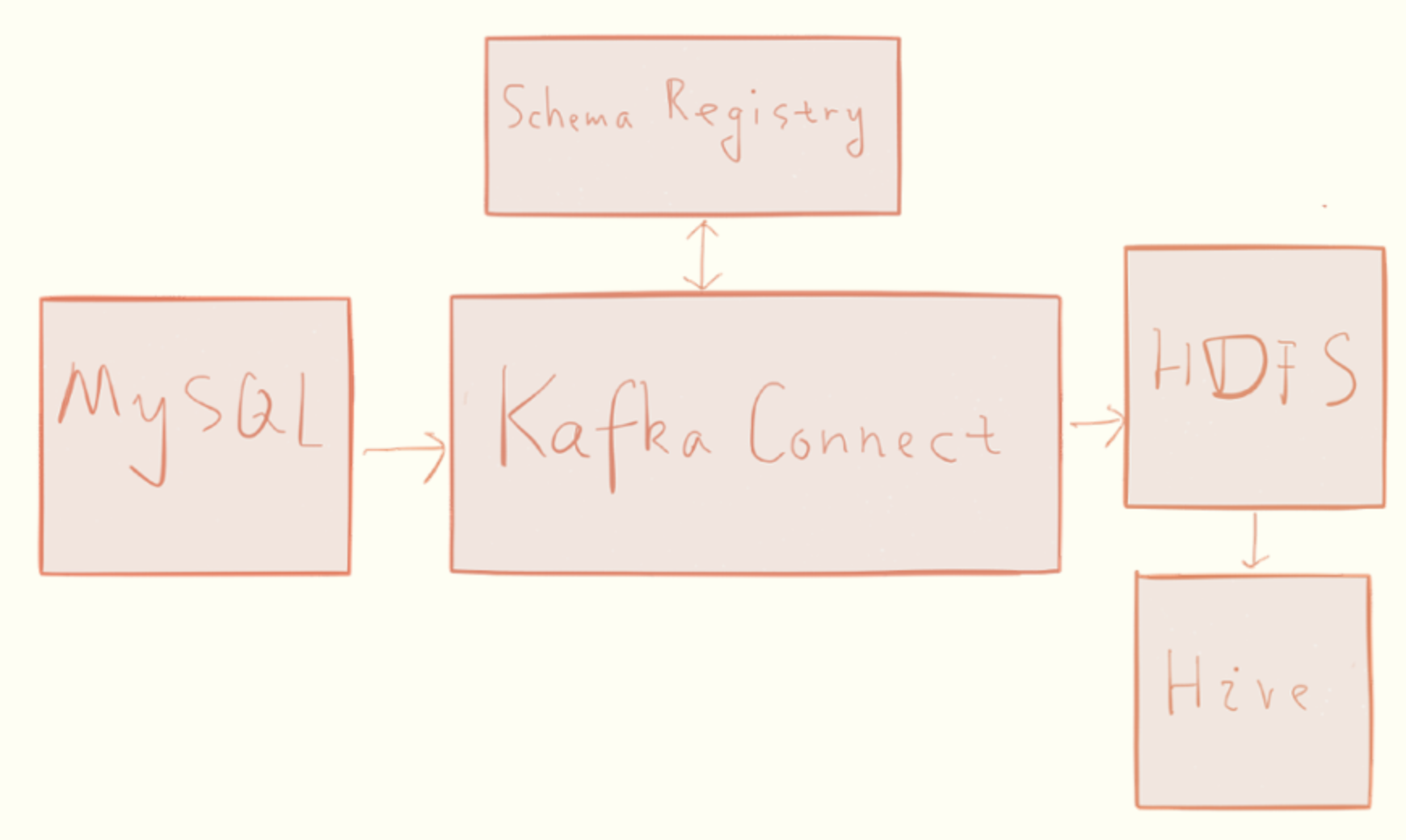
最开始接触confluent是通过这篇博客,How to Build a Scalable ETL Pipeline with Kafka Connect,对于做大数据的,数据的ETL(抽取,转换,装载)是必不可少的。例如,要把传统的关系型数据库中的数据导入到HDFS里,或者导入到Hive中,进一步对数据进行分析,或者把json或者文本文件中的数据导入到大数据数据仓库中进行分析。这都需要ETL。这篇文章介绍了如何利用confluent的相关组件(Kafka Connect,构建一个ETL pipeline.下图来自于这篇博客。有兴趣的可以看一下这篇博客。
Building a Scalable ETL Pipeline in 30 Minutes
confluent介绍:
LinkedIn有个三人小组出来创业了—正是当时开发出Apache Kafka实时信息列队技术的团队成员,基于这项技术Jay Kreps带头创立了新公司Confluent。Confluent的产品围绕着Kafka做的。
什么是Confluent Platform?
Confluent Platform 是一个流数据平台,能够组织管理来自不同数据源的数据,拥有稳定高效的系统。
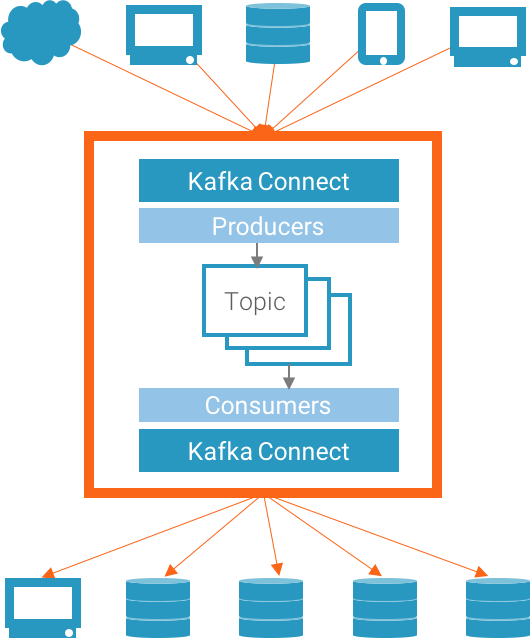

Confluent Platform 不仅提供数据传输的系统, 还提供所有的工具:连接数据源的工具,应用, 以及数据接收。
Confluent Platform 都包括什么?
Confluent Platform 很容易的建立实时数据管道和流应用。通过将多个来源和位置的数据集成到公司一个中央数据流平台,Confluent Platform使您可以专注于如何从数据中获得商业价值而不是担心底层机制,如数据是如何被运输或不同系统间摩擦。具体来说,Confluent Platform简化了连接数据源到Kafka,用Kafka构建应用程序,以及安全,监控和管理您的Kafka的基础设施。
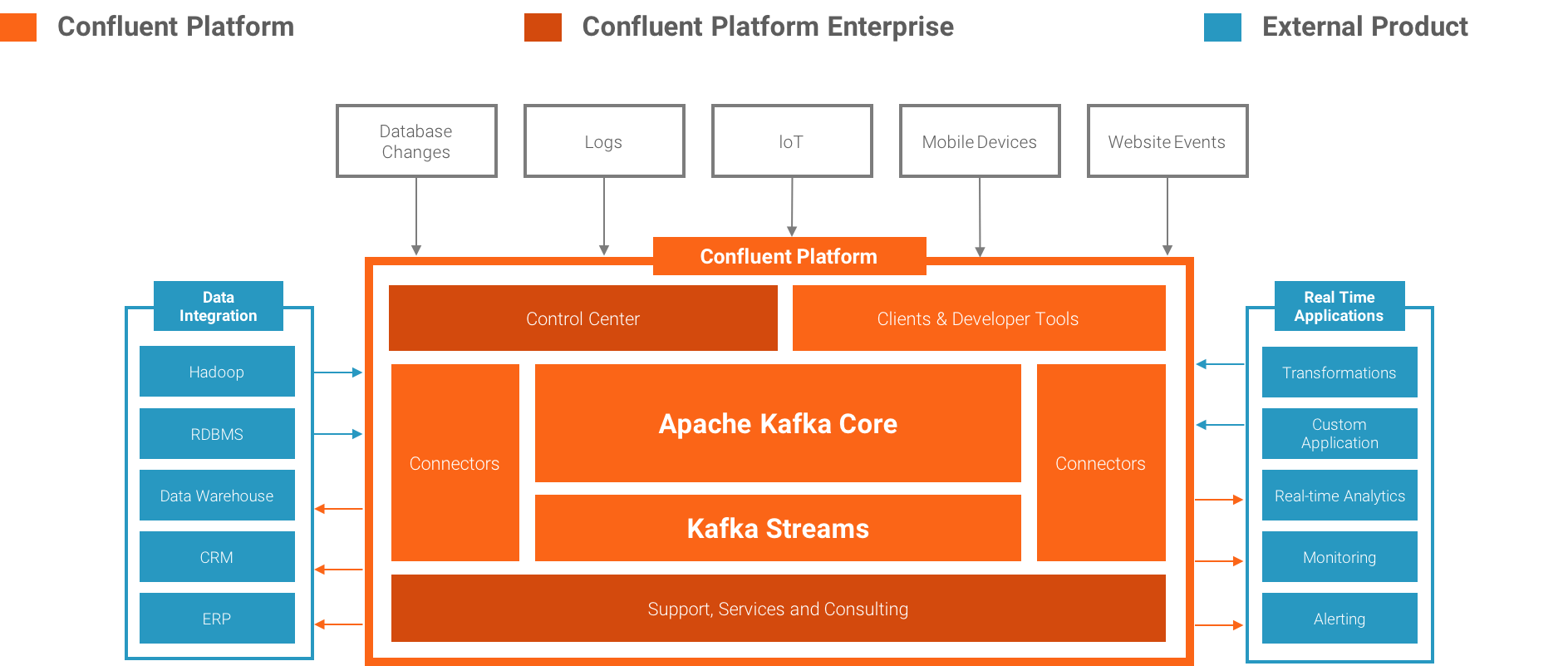

Kafka 是最流行的开源即时通讯系统,Confluent Platform 基于Kafka. Kafka 是低延迟,高可扩展,分布式消息系统。它被数百家企业用于许多不同的场景,包括收集用户活动数据,系统日志,应用程序指标,股票行情数据和设备仪器的信号。
Kafka开源项目包括一些关键组件:
Kafka Brokers(开源)。构成Kafka的消息,数据持久性和存储层。
Kafka Java Clients(开源)。Java 库,写消息到kafka 或者从kafka 读消息。
Kafka Streams(开源)。Kafka Streams是一个库使kafka转换成功能齐全的流处理系统。
Kafka Connect(开源)。一种可扩展的和可靠的连接Kafka框架与外部系统(如数据库,键值存储,搜索索引和文件系统)的框架。
除了Kafka以外, Confluent Platform 包括更多的工具和服务,使构建和管理数据流平台更加容易。
Confluent Control Center(闭源)。管理和监控Kafka最全面的GUI驱动系统。
Confluent Kafka Connectors(开源)。连接SQL数据库/Hadoop/Hive
Confluent Kafka Clients(开源)。对于其他编程语言,包括C/C++,Python
Confluent Kafka REST Proxy(开源)。允许一些系统通过HTTP和kafka之间发送和接收消息。
Confluent Schema Registry(开源)。帮助确定每一个应用使用正确的schema当写数据或者读数据到kafka中。
总的来说,Confluent Platform平台的组件给你的团队朝着建立统一而灵活的方式建立一个企业范围的数据流平台。
随后,我们会通过一些quickstart来介绍Confluent 的核心组件。
下载
http://www.confluent.io/download,打开后,显示最新版本3.0.0,然后在右边填写信息后,点击Download下载。
之后跳转到下载页面,选择zip 或者 tar都行, 下载完成后上传linux系统,解压即完成安装。
- zip and tar archives – 推荐OS X 和 Quickstart
- deb packages via apt – 推荐安装服务在 Debian/Ubuntu系统
- rpm packages via yum – 推荐安装服务在 RHEL/CentOS/Fedora系统
- deb/rpm packages with installer script
Confluent 目前还不支持Windows系统。Windows用户可以下载和使用zip 和 tar包,但最好直接运行jar文件 ,而不是使用包装脚本。
Requirements
唯一需要的条件是java 版本>=1.7。
Confluent Platform Quickstart
你可以快速的运行Confluent platform在单台服务器上。在这篇quickstart,我们将介绍如何运行ZooKeeper,Kafka,和Schema Registry,然后如何读和写一些Avro数据从/到Kafka。
(如果你想跑一个数据管道用Kafka Connect和Control Center,参考The Control Center QuickStart Guide.)我们随后也会介绍。
1.下载和安装Confluent platform。在这篇quickstart 我们使用zip包,也有很多其他安装方式,见上。
$ wget http://packages.confluent.io/archive/3.0/confluent-3.0.0-2.11.zip $ unzip confluent-3.0.0-2.11.zip $ cd confluent-3.0.0
下边展示的是安装目录里上层层级结构:
confluent-3.0.0/bin/ # Driver scripts for starting/stopping services confluent-3.0.0/etc/ # Configuration files confluent-3.0.0/share/java/ # Jars
如果你通过deb或者rpm安装,目录结构如下:
/usr/bin/ # Driver scripts for starting/stopping services, prefixed with <package> names /etc/<package>/ # Configuration files /usr/share/java/<package>/ # Jars
2.启动Zookeeper。因为这是长期运行的服务,你应该运行它在一个独立的终端(或者在后边运行它,重定向输出到一个文件中)。你需要有写权限到/var/lib在这一步以及之后的步骤里:
# The following commands assume you exactly followed the instructions above. # This means, for example, that at this point your current working directory # must be confluent-3.0.0/. $ ./bin/zookeeper-server-start ./etc/kafka/zookeeper.properties
3.启动Kafka,同样在一个独立的终端。
$ ./bin/kafka-server-start ./etc/kafka/server.properties
4.启动Schema Registry,同样在一个独立的终端。
$ ./bin/schema-registry-start ./etc/schema-registry/schema-registry.properties
5.现在所有需要的服务都已启动,我们发送一些Avro数据到Kafka的topic中。虽然这一步一般会得到一些数据从一些应用里,这里我们使用Kafka提供的例子,不用写代码。我们在本地的Kafka集群里,写数据到topic “test”里,读取每一行Avro信息,校验Schema Registry .
$ ./bin/kafka-avro-console-producer \
--broker-list localhost:9092 --topic test \
--property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
一旦启动,进程等待你输入一些信息,一条一行,会发送到topic中一旦按下enter键。试着输入一些信息:
{"f1": "value1"}
{"f1": "value2"}
{"f1": "value3"}
输入完成后,可以使用Ctrl+C来终止进程。
Note:如果一个空行你按下Enter键,会被解释为一个null值,引起错误。然后仅仅需要做的是启动producer进程,接着输入信息。
6.现在我们可以检查,通过Kafka consumer控制台读取数据从topic。在topic ‘test’中,Zookeeper实例,会告诉consumer解析数据使用相同的schema。最后从开始读取数据(默认consumer只读取它启动之后写入到topic中的数据)
$ ./bin/kafka-avro-console-consumer --topic test \
--zookeeper localhost:2181 \
--from-beginning
你会看到你之前在producer中输入的数据,以同样的格式。
consumer不会退出,它可以监听写入到topic中的新数据。保持consumer运行,然后重复第5步,输入一些信息,然后按下enter键,你会看到consumer会立即读取到写入到topic中的数据。
当你完成了测试,可以用Ctrl+C终止进程。
7.现在让我们尝试写一些不兼容的schema的数据到topic ’test‘中,我们重新运行producer命令,但是改变schema。
$ ./bin/kafka-avro-console-producer \
--broker-list localhost:9092 --topic test \
--property value.schema='{"type":"int"}'
现在输入一个整数按下enter键,你会看到以下的异常:
org.apache.kafka.common.errors.SerializationException: Error registering Avro schema: "int"
Caused by: io.confluent.kafka.schemaregistry.client.rest.exceptions.RestClientException: Schema being registered is incompatible with the latest schema; error code: 409
at io.confluent.kafka.schemaregistry.client.rest.utils.RestUtils.httpRequest(RestUtils.java:146)
at io.confluent.kafka.schemaregistry.client.rest.utils.RestUtils.registerSchema(RestUtils.java:174)
at io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient.registerAndGetId(CachedSchemaRegistryClient.java:51)
at io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient.register(CachedSchemaRegistryClient.java:89)
at io.confluent.kafka.serializers.AbstractKafkaAvroSerializer.serializeImpl(AbstractKafkaAvroSerializer.java:49)
at io.confluent.kafka.formatter.AvroMessageReader.readMessage(AvroMessageReader.java:155)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:94)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
当producer试图发送一些信息,它会检查schema用Schema Registry。当返回错误时说明现在的schema无效,因为它不能兼容之前设置的schema。控制台打印出错误信息并退出,但是你自己的应用可以更加人性化处理这类问题。但最重要的是,我们保证不让不兼容的数据写入到Kafka中。
8.当你完成这一系列测试,你可以使用ctrl+c来关闭服务,以启动时相反的顺序。
这一简单的教程包含了Kafka和Schema Registry这一些核心的服务。你也可以参考以下document:
- Confluent Control Center documentation
- Kafka Streams documentation
- Kafka Connect documentation
- Schema Registry documentation
- Kafka REST Proxy documentation
- Camus documentation