Leave a Comment
1、Mysql 高可用(HA)的架构大致可以分成:
- 集群:多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管;
- 基于复制的方式:主要思想是通过mysql的二进制日志进行主-从、主-主同步,不同主机之间通过keepalived或者heartbeat软件进行双机热备。当有一台机器发生故障,keepalived(或者heartbeat)会自动切换到备机继续提供服务。这种方式、又分为以下两种:
- 主备方式:主机工作,备机处于监控准备状况;当主机宕机时,备机接管主机的一切工作。通常用作读写分离(单点写入),由于主备方式中的复制往往都是单向的,所以在备机上的写入操作无法复制到主机;
- 主主方式:两台主机同时运行各自的服务工作且相互监测情况,当任一台主机宕机时,另一台主机立即接管它的一切工作,待主机恢复正常后,按使用者的设定以自动或手动方式将服务切换到主机上运行;
注:为了保证数据的一致性,所以即使是主-主方式,通常也是单点写入,另一台主机作为备机。
2、脑裂:
1)什么是脑裂?
在心跳失效的时候,就发生了脑裂(split-brain)。
一种常见的脑裂情况可以描述如下,比如正常情况下,(集群中的)NodeA 和 NodeB 会通过心跳检测以确认对方存在,在通过心跳检测确认不到对方存在时,就接管对应的(共享) resource 。如果突然间,NodeA 和 NodeB 之间的心跳不存在了(如网络断开),而 NodeA 和 NodeB 事实上却都处于 Active 状态,此时 NodeA 要接管 NodeB 的 resource ,同时 NodeB 要接管 NodeA 的 resource ,这时就是脑裂(split-brain)。
2)影响:
脑裂(split-brain)会 引起数据的不完整性 ,并且可能会 对服务造成严重影响 。这时由于,集群中节点(在脑裂期间)同时访问同一共享资源,而此时并没有锁机制来控制针对该数据访问(都脑裂了,咋控制哩),那么就存在数据的不完整性的可能。
3)解决方法:
- 添加冗余的心跳线。例如双“心跳线”。尽量减少“裂脑”发生机会。
- 启用磁盘锁。
- 设置仲裁机制。
mysql 集群(cluster)
MySQL Cluster实际上是在无共享存储设备(Shared Nothing)的情况下实现的一种完全分布式数据库系统,其主要通过 NDBCluster(简称NDB)存储引擎来实现。
MySQL Cluster 由一组计算机构成,每台计算机上均运行着多种进程,包括MySQL服务器,NDB Cluster 的数据节点,管理服务器,以及(可能)专门的数据访问程序。关于 Cluster 中这些组件的关系,请参见下图:

虽然Mysql Cluster一直再不断的改进,但由于种种原因,一直在业界没有流行起来。
基于复制的高可用
1、主从复制+keepalived
描述:两台主机搭建了一个mysql主从复制的环境;两台机器分别安装了keepalived,用一个虚IP(VIP)实现mysql服务器的主备自动切换功能。当master宕掉后,keepalived会自动接管这个VIP,使用slave继续提供服务。在这样的集群中,Master对外提供全部的服务,Slave处于备份状态。
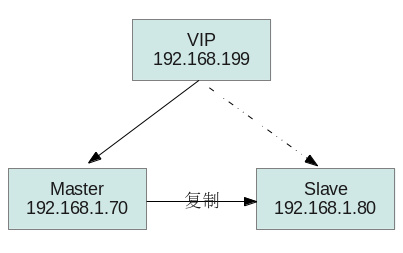
- 优点:简单、可以提供一致性;
- 缺点:只有一台机器提供服务;切换到slave后,在其上面的写入操作无法同步回master
配置过程如下:(70为master、slavery为slave、199为VIP)
1)在70、80两台机子上部署mysql主从复制。详情见这里
2)安装keepalived。详情见这里
3)配置keepalived文件:
在master(70)上的vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id HA_MySQL } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 nopreempt authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.1.199 } } virtual_server 192.168.1.199 3306 { delay_loop 2 lb_algo wrr lb_kind DR persistence_timeout 60 protocol TCP real_server 192.168.1.70 3306 { weight 3 notify_down /root/shutdown.sh TCP_CHECK { connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 3306 } } } |
在slave(80)上vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs { router_id HA_MySQL } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 90 advert_int 1 nopreempt authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.1.199 } } virtual_server 192.168.1.199 3306 { delay_loop 2 lb_algo wrr lb_kind DR persistence_timeout 60 protocol TCP real_server 192.168.1.80 3306 { weight 3 notify_down /root/shutdown.sh TCP_CHECK { connect_timeout 10 nb_get_retry 3 delay_before_retry 3 connect_port 3306 } } } |
4)shutdown.sh 文件:
可以考虑加入邮件告警的功能:
#!/bin/bash pkill keepalived |
5)在master、slave分别启动mysql和keepalived:
service mysql start
service keepalived start
6)测试:
在master上kiil mysql后,keepalived检测到3306端口无法通信后会自杀(通过shutdown.sh实现)。然后slave上的keepalived会自动接管VIP,提供服务。
2、主备方式+DRBD:
这种架构同上,也是单点写入;唯一的区别是使用了DRBD代替了主从复制。
3、主-主复制 单点写入+keepalived:
同方式1,也是单点写入。区别是mysql的主从复制改为了主-主复制。
4、MMM高可用方案:
MMM即Master-Master Replication Manager for MySQL(mysql主主复制管理器)关于mysql主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件(在任何时候只有一个节点可以被写入),这个套件也能对居于标准的主从配置的任意数量的从服务器进行读负载均衡,所以你可以用它来在一组居于复制的服务器启动虚拟ip,除此之外,它还有实现数据备份、节点之间重新同步功能的脚本。
MySQL本身没有提供replication failover的解决方案,通过MMM方案能实现服务器的故障转移,从而实现mysql的高可用。MMM不仅能提供浮动IP的功能,更可贵的是如果当前的主服务器挂掉后,会将你后端的从服务器自动转向新的主服务器进行同步复制,不用手工更改同步配置。这个方案是目前比较成熟的解决方案。
